Antoine Beaupr : A ZFS migration
In my tubman setup, I started using ZFS on an old server
I had lying around. The machine is really old though (2011!) and it
"feels" pretty slow. I want to see how much of that is ZFS and how
much is the machine. Synthetic benchmarks show that ZFS may be slower
than mdadm in RAID-10 or RAID-6 configuration, so I want to confirm
that on a live workload: my workstation. Plus, I want easy, regular,
high performance backups (with send/receive snapshots) and there's no
way I'm going to use BTRFS because I find
it too confusing and unreliable.
So off we go.
Installation
Since this is a conversion (and not a new install), our procedure is
slightly different than the official documentation but otherwise
it's pretty much in the same spirit: we're going to use ZFS for
everything, including the root filesystem.
So, install the required packages, on the current system:
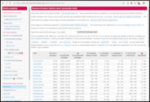
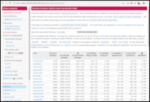
Peaks are at about 20k IOPS and ~1.3GiB/s read, 1GiB/s write in the
64KB blocks with 16 jobs.
Slowest is the random 4k block sync write at an abysmal 3MB/s and 700
IOPS The 1MB read/write tests have lower IOPS, but that is expected.
Peaks are at 1.8GiB/s read, also in the 64k job like above, but much
faster. The write is, as expected, much slower at 70MiB/s (compared
to 1GiB/s!), but it should be noted the sync write doesn't degrade
performance compared to async writes (although it's still below the
LVM 300MB/s).
Conclusions
Really, ZFS has trouble performing in all write conditions. The
random 4k sync write test is the only place where ZFS outperforms
LVM in writes, and barely (7MiB/s vs 3MiB/s). Everywhere else, writes
are much slower, sometimes by an order of magnitude.
And before some ZFS zealot jumps in talking about the SLOG or some
other cache that could be added to improved performance, I'll remind
you that those numbers are on a bare bones NVMe drive, pretty much as
fast storage as you can find on this machine. Adding another NVMe
drive as a cache probably will not improve write performance here.
Still, those are very different results than the tests performed by
Salter which shows ZFS beating traditional configurations in all
categories but uncached 4k reads (not writes!). That said, those tests
are very different from the tests I performed here, where I test
writes on a single disk, not a RAID array, which might explain the
discrepancy.
Also, note that neither LVM or ZFS manage to reach the 2400MB/s read
and 1750MB/s write performance specification. ZFS does manage to reach
82% of the read performance (1973MB/s) and LVM 64% of the write
performance (1120MB/s). LVM hits 57% of the read performance and ZFS
hits barely 6% of the write performance.
Overall, I'm a bit disappointed in the ZFS write performance here, I
must say. Maybe I need to tweak the record size or some other ZFS
voodoo, but I'll note that I didn't have to do any such configuration
on the other side to kick ZFS in the pants...
Installation
Since this is a conversion (and not a new install), our procedure is
slightly different than the official documentation but otherwise
it's pretty much in the same spirit: we're going to use ZFS for
everything, including the root filesystem.
So, install the required packages, on the current system:
apt install --yes gdisk zfs-dkms zfs zfs-initramfs zfsutils-linux
We also tell DKMS that we need to rebuild the initrd when upgrading:
echo REMAKE_INITRD=yes > /etc/dkms/zfs.conf
Partitioning
This is going to partition /dev/sdc with:
- 1MB MBR / BIOS legacy boot
- 512MB EFI boot
- 1GB bpool, unencrypted pool for /boot
- rest of the disk for zpool, the rest of the data
sgdisk --zap-all /dev/sdc
sgdisk -a1 -n1:24K:+1000K -t1:EF02 /dev/sdc
sgdisk -n2:1M:+512M -t2:EF00 /dev/sdc
sgdisk -n3:0:+1G -t3:BF01 /dev/sdc
sgdisk -n4:0:0 -t4:BF00 /dev/sdc
That will look something like this:
root@curie:/home/anarcat# sgdisk -p /dev/sdc
Disk /dev/sdc: 1953525168 sectors, 931.5 GiB
Model: ESD-S1C
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): [REDACTED]
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 1953525134
Partitions will be aligned on 16-sector boundaries
Total free space is 14 sectors (7.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 48 2047 1000.0 KiB EF02
2 2048 1050623 512.0 MiB EF00
3 1050624 3147775 1024.0 MiB BF01
4 3147776 1953525134 930.0 GiB BF00
Unfortunately, we can't be sure of the sector size here, because the
USB controller is probably lying to us about it. Normally, this
smartctl command should tell us the sector size as well:
root@curie:~# smartctl -i /dev/sdb -qnoserial
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-14-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Black Mobile
Device Model: WDC WD10JPLX-00MBPT0
Firmware Version: 01.01H01
User Capacity: 1 000 204 886 016 bytes [1,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue May 17 13:33:04 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Above is the example of the builtin HDD drive. But the SSD device
enclosed in that USB controller doesn't support SMART commands,
so we can't trust that it really has 512 bytes sectors.
This matters because we need to tweak the ashift value
correctly. We're going to go ahead the SSD drive has the common 4KB
settings, which means ashift=12.
Note here that we are not creating a separate partition for
swap. Swap on ZFS volumes (AKA "swap on ZVOL") can trigger lockups and
that issue is still not fixed upstream. Ubuntu recommends using a
separate partition for swap instead. But since this is "just" a
workstation, we're betting that we will not suffer from this problem,
after hearing a report from another Debian developer running this
setup on their workstation successfully.
We do not recommend this setup though. In fact, if I were to redo this
partition scheme, I would probably use LUKS encryption and setup a
dedicated swap partition, as I had problems with ZFS encryption as
well.
Creating pools
ZFS pools are somewhat like "volume groups" if you are familiar with
LVM, except they obviously also do things like RAID-10. (Even though
LVM can technically also do RAID, people typically use mdadm
instead.)
In any case, the guide suggests creating two different pools here:
one, in cleartext, for boot, and a separate, encrypted one, for the
rest. Technically, the boot partition is required because the Grub
bootloader only supports readonly ZFS pools, from what I
understand. But I'm a little out of my depth here and just following
the guide.
Boot pool creation
This creates the boot pool in readonly mode with features that grub
supports:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O canmount=off \
-O compression=lz4 \
-O devices=off -O normalization=formD -O relatime=on -O xattr=sa \
-O mountpoint=/boot -R /mnt \
bpool /dev/sdc3
I haven't investigated all those settings and just trust the upstream
guide on the above.
Main pool creation
This is a more typical pool creation.
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool /dev/sdc4
Breaking this down:
-o ashift=12: mentioned above, 4k sector size-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off-O canmount=off: do not make the pool mount automatically with
mount -a?-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now
Those settings are all available in zfsprops(8). Other flags are
defined in zpool-create(8). The reasoning behind them is also
explained in the upstream guide and some also in [the Debian
wiki][]. Those flags were actually not used:
-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.
[the Debian
wiki]: https://wiki.debian.org/ZFS#Advanced_Topics
Side note about single-disk pools
Also note that we're living dangerously here: single-disk ZFS pools
are rumoured to be more dangerous than not running ZFS at all. The
choice quote from this article is:
[...] any error can be detected, but cannot be corrected. This
sounds like an acceptable compromise, but its actually not. The
reason its not is that ZFS' metadata cannot be allowed to be
corrupted. If it is it is likely the zpool will be impossible to
mount (and will probably crash the system once the corruption is
found). So a couple of bad sectors in the right place will mean that
all data on the zpool will be lost. Not some, all. Also there's no
ZFS recovery tools, so you cannot recover any data on the drives.
Compared with (say) ext4, where a single disk error can recovered,
this is pretty bad. But we are ready to live with this with the idea
that we'll have hourly offline snapshots that we can easily recover
from. It's trade-off. Also, we're running this on a NVMe/M.2 drive
which typically just blinks out of existence completely, and doesn't
"bit rot" the way a HDD would.
Also, the FreeBSD handbook quick start doesn't have any warnings
about their first example, which is with a single disk. So I am
reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
- this creates two containers, for
ROOT and BOOT
zfs create -o canmount=off -o mountpoint=none rpool/ROOT &&
zfs create -o canmount=off -o mountpoint=none bpool/BOOT
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
- this creates the actual boot and root filesystems:
zfs create -o canmount=noauto -o mountpoint=/ rpool/ROOT/debian &&
zfs mount rpool/ROOT/debian &&
zfs create -o mountpoint=/boot bpool/BOOT/debian
I guess the debian name here is because we could technically have
multiple operating systems with the same underlying datasets.
- then the main datasets:
zfs create rpool/home &&
zfs create -o mountpoint=/root rpool/home/root &&
chmod 700 /mnt/root &&
zfs create rpool/var
- exclude temporary files from snapshots:
zfs create -o com.sun:auto-snapshot=false rpool/var/cache &&
zfs create -o com.sun:auto-snapshot=false rpool/var/tmp &&
chmod 1777 /mnt/var/tmp
- and skip automatic snapshots in Docker:
zfs create -o canmount=off rpool/var/lib &&
zfs create -o com.sun:auto-snapshot=false rpool/var/lib/docker
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
echo ' "storage-driver": "zfs" ' > /etc/docker/daemon.json
Note that podman has the same problem (and similar solution):
printf '[storage]\ndriver = "zfs"\n' > /etc/containers/storage.conf
- make a
tmpfs for /run:
mkdir /mnt/run &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
We don't create a /srv, as that's the HDD stuff.
Also mount the EFI partition:
mkfs.fat -F 32 /dev/sdc2 &&
mount /dev/sdc2 /mnt/boot/efi/
At this point, everything should be mounted in /mnt. It should look
like this:
root@curie:~# LANG=C df -h -t zfs -t vfat
Filesystem Size Used Avail Use% Mounted on
rpool/ROOT/debian 899G 384K 899G 1% /mnt
bpool/BOOT/debian 832M 123M 709M 15% /mnt/boot
rpool/home 899G 256K 899G 1% /mnt/home
rpool/home/root 899G 256K 899G 1% /mnt/root
rpool/var 899G 384K 899G 1% /mnt/var
rpool/var/cache 899G 256K 899G 1% /mnt/var/cache
rpool/var/tmp 899G 256K 899G 1% /mnt/var/tmp
rpool/var/lib/docker 899G 256K 899G 1% /mnt/var/lib/docker
/dev/sdc2 511M 4.0K 511M 1% /mnt/boot/efi
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
cat > /etc/systemd/system/zfs-import-bpool.service <<EOF
[Unit]
DefaultDependencies=no
Before=zfs-import-scan.service
Before=zfs-import-cache.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/sbin/zpool import -N -o cachefile=none bpool
# Work-around to preserve zpool cache:
ExecStartPre=-/bin/mv /etc/zfs/zpool.cache /etc/zfs/preboot_zpool.cache
ExecStartPost=-/bin/mv /etc/zfs/preboot_zpool.cache /etc/zfs/zpool.cache
[Install]
WantedBy=zfs-import.target
EOF
Enable the service:
systemctl enable zfs-import-bpool.service
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
ln -s /usr/share/systemd/tmp.mount /etc/systemd/system/ &&
systemctl enable tmp.mount
Rebuild boot loader with support for ZFS, but also to workaround
GRUB's missing zpool-features support:
grub-probe /boot grep -q zfs &&
update-initramfs -c -k all &&
sed -i 's,GRUB_CMDLINE_LINUX.*,GRUB_CMDLINE_LINUX="root=ZFS=rpool/ROOT/debian",' /etc/default/grub &&
update-grub
For good measure, make sure the right disk is configured here, for
example you might want to tag both drives in a RAID array:
dpkg-reconfigure grub-pc
Install grub to EFI while you're there:
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian --recheck --no-floppy
Filesystem mount ordering. The rationale here in the OpenZFS
guide is a little strange, but I don't dare ignore that.
mkdir /etc/zfs/zfs-list.cache
touch /etc/zfs/zfs-list.cache/bpool
touch /etc/zfs/zfs-list.cache/rpool
zed -F &
Verify that zed updated the cache by making sure these are not empty:
cat /etc/zfs/zfs-list.cache/bpool
cat /etc/zfs/zfs-list.cache/rpool
Once the files have data, stop zed:
fg
Press Ctrl-C.
Fix the paths to eliminate /mnt:
sed -Ei "s /mnt/? / " /etc/zfs/zfs-list.cache/*
Snapshot initial install:
zfs snapshot bpool/BOOT/debian@install
zfs snapshot rpool/ROOT/debian@install
Exit chroot:
exit
Finalizing
One last sync was done in rescue mode:
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
Then we unmount all filesystems:
mount grep -v zfs tac awk '/\/mnt/ print $3 ' xargs -i umount -lf
zpool export -a
Reboot, swap the drives, and boot in ZFS. Hurray!
Benchmarks
This is a test that was ran in single-user mode using fio and the Ars
Technica recommended tests, which are:
- Single 4KiB random write process:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
- 16 parallel 64KiB random write processes:
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
- Single 1MiB random write process:
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
apt install --yes gdisk zfs-dkms zfs zfs-initramfs zfsutils-linux
echo REMAKE_INITRD=yes > /etc/dkms/zfs.conf
/dev/sdc with:
- 1MB MBR / BIOS legacy boot
- 512MB EFI boot
- 1GB bpool, unencrypted pool for /boot
- rest of the disk for zpool, the rest of the data
sgdisk --zap-all /dev/sdc sgdisk -a1 -n1:24K:+1000K -t1:EF02 /dev/sdc sgdisk -n2:1M:+512M -t2:EF00 /dev/sdc sgdisk -n3:0:+1G -t3:BF01 /dev/sdc sgdisk -n4:0:0 -t4:BF00 /dev/sdc
root@curie:/home/anarcat# sgdisk -p /dev/sdc
Disk /dev/sdc: 1953525168 sectors, 931.5 GiB
Model: ESD-S1C
Sector size (logical/physical): 512/512 bytes
Disk identifier (GUID): [REDACTED]
Partition table holds up to 128 entries
Main partition table begins at sector 2 and ends at sector 33
First usable sector is 34, last usable sector is 1953525134
Partitions will be aligned on 16-sector boundaries
Total free space is 14 sectors (7.0 KiB)
Number Start (sector) End (sector) Size Code Name
1 48 2047 1000.0 KiB EF02
2 2048 1050623 512.0 MiB EF00
3 1050624 3147775 1024.0 MiB BF01
4 3147776 1953525134 930.0 GiB BF00
smartctl command should tell us the sector size as well:
root@curie:~# smartctl -i /dev/sdb -qnoserial
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-14-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Black Mobile
Device Model: WDC WD10JPLX-00MBPT0
Firmware Version: 01.01H01
User Capacity: 1 000 204 886 016 bytes [1,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Tue May 17 13:33:04 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
ashift value
correctly. We're going to go ahead the SSD drive has the common 4KB
settings, which means ashift=12.
Note here that we are not creating a separate partition for
swap. Swap on ZFS volumes (AKA "swap on ZVOL") can trigger lockups and
that issue is still not fixed upstream. Ubuntu recommends using a
separate partition for swap instead. But since this is "just" a
workstation, we're betting that we will not suffer from this problem,
after hearing a report from another Debian developer running this
setup on their workstation successfully.
We do not recommend this setup though. In fact, if I were to redo this
partition scheme, I would probably use LUKS encryption and setup a
dedicated swap partition, as I had problems with ZFS encryption as
well.
Creating pools
ZFS pools are somewhat like "volume groups" if you are familiar with
LVM, except they obviously also do things like RAID-10. (Even though
LVM can technically also do RAID, people typically use mdadm
instead.)
In any case, the guide suggests creating two different pools here:
one, in cleartext, for boot, and a separate, encrypted one, for the
rest. Technically, the boot partition is required because the Grub
bootloader only supports readonly ZFS pools, from what I
understand. But I'm a little out of my depth here and just following
the guide.
Boot pool creation
This creates the boot pool in readonly mode with features that grub
supports:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O canmount=off \
-O compression=lz4 \
-O devices=off -O normalization=formD -O relatime=on -O xattr=sa \
-O mountpoint=/boot -R /mnt \
bpool /dev/sdc3
I haven't investigated all those settings and just trust the upstream
guide on the above.
Main pool creation
This is a more typical pool creation.
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool /dev/sdc4
Breaking this down:
-o ashift=12: mentioned above, 4k sector size-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off-O canmount=off: do not make the pool mount automatically with
mount -a?-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now
Those settings are all available in zfsprops(8). Other flags are
defined in zpool-create(8). The reasoning behind them is also
explained in the upstream guide and some also in [the Debian
wiki][]. Those flags were actually not used:
-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.
[the Debian
wiki]: https://wiki.debian.org/ZFS#Advanced_Topics
Side note about single-disk pools
Also note that we're living dangerously here: single-disk ZFS pools
are rumoured to be more dangerous than not running ZFS at all. The
choice quote from this article is:
[...] any error can be detected, but cannot be corrected. This
sounds like an acceptable compromise, but its actually not. The
reason its not is that ZFS' metadata cannot be allowed to be
corrupted. If it is it is likely the zpool will be impossible to
mount (and will probably crash the system once the corruption is
found). So a couple of bad sectors in the right place will mean that
all data on the zpool will be lost. Not some, all. Also there's no
ZFS recovery tools, so you cannot recover any data on the drives.
Compared with (say) ext4, where a single disk error can recovered,
this is pretty bad. But we are ready to live with this with the idea
that we'll have hourly offline snapshots that we can easily recover
from. It's trade-off. Also, we're running this on a NVMe/M.2 drive
which typically just blinks out of existence completely, and doesn't
"bit rot" the way a HDD would.
Also, the FreeBSD handbook quick start doesn't have any warnings
about their first example, which is with a single disk. So I am
reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
- this creates two containers, for
ROOT and BOOT
zfs create -o canmount=off -o mountpoint=none rpool/ROOT &&
zfs create -o canmount=off -o mountpoint=none bpool/BOOT
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
- this creates the actual boot and root filesystems:
zfs create -o canmount=noauto -o mountpoint=/ rpool/ROOT/debian &&
zfs mount rpool/ROOT/debian &&
zfs create -o mountpoint=/boot bpool/BOOT/debian
I guess the debian name here is because we could technically have
multiple operating systems with the same underlying datasets.
- then the main datasets:
zfs create rpool/home &&
zfs create -o mountpoint=/root rpool/home/root &&
chmod 700 /mnt/root &&
zfs create rpool/var
- exclude temporary files from snapshots:
zfs create -o com.sun:auto-snapshot=false rpool/var/cache &&
zfs create -o com.sun:auto-snapshot=false rpool/var/tmp &&
chmod 1777 /mnt/var/tmp
- and skip automatic snapshots in Docker:
zfs create -o canmount=off rpool/var/lib &&
zfs create -o com.sun:auto-snapshot=false rpool/var/lib/docker
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
echo ' "storage-driver": "zfs" ' > /etc/docker/daemon.json
Note that podman has the same problem (and similar solution):
printf '[storage]\ndriver = "zfs"\n' > /etc/containers/storage.conf
- make a
tmpfs for /run:
mkdir /mnt/run &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
We don't create a /srv, as that's the HDD stuff.
Also mount the EFI partition:
mkfs.fat -F 32 /dev/sdc2 &&
mount /dev/sdc2 /mnt/boot/efi/
At this point, everything should be mounted in /mnt. It should look
like this:
root@curie:~# LANG=C df -h -t zfs -t vfat
Filesystem Size Used Avail Use% Mounted on
rpool/ROOT/debian 899G 384K 899G 1% /mnt
bpool/BOOT/debian 832M 123M 709M 15% /mnt/boot
rpool/home 899G 256K 899G 1% /mnt/home
rpool/home/root 899G 256K 899G 1% /mnt/root
rpool/var 899G 384K 899G 1% /mnt/var
rpool/var/cache 899G 256K 899G 1% /mnt/var/cache
rpool/var/tmp 899G 256K 899G 1% /mnt/var/tmp
rpool/var/lib/docker 899G 256K 899G 1% /mnt/var/lib/docker
/dev/sdc2 511M 4.0K 511M 1% /mnt/boot/efi
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
cat > /etc/systemd/system/zfs-import-bpool.service <<EOF
[Unit]
DefaultDependencies=no
Before=zfs-import-scan.service
Before=zfs-import-cache.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/sbin/zpool import -N -o cachefile=none bpool
# Work-around to preserve zpool cache:
ExecStartPre=-/bin/mv /etc/zfs/zpool.cache /etc/zfs/preboot_zpool.cache
ExecStartPost=-/bin/mv /etc/zfs/preboot_zpool.cache /etc/zfs/zpool.cache
[Install]
WantedBy=zfs-import.target
EOF
Enable the service:
systemctl enable zfs-import-bpool.service
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
ln -s /usr/share/systemd/tmp.mount /etc/systemd/system/ &&
systemctl enable tmp.mount
Rebuild boot loader with support for ZFS, but also to workaround
GRUB's missing zpool-features support:
grub-probe /boot grep -q zfs &&
update-initramfs -c -k all &&
sed -i 's,GRUB_CMDLINE_LINUX.*,GRUB_CMDLINE_LINUX="root=ZFS=rpool/ROOT/debian",' /etc/default/grub &&
update-grub
For good measure, make sure the right disk is configured here, for
example you might want to tag both drives in a RAID array:
dpkg-reconfigure grub-pc
Install grub to EFI while you're there:
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian --recheck --no-floppy
Filesystem mount ordering. The rationale here in the OpenZFS
guide is a little strange, but I don't dare ignore that.
mkdir /etc/zfs/zfs-list.cache
touch /etc/zfs/zfs-list.cache/bpool
touch /etc/zfs/zfs-list.cache/rpool
zed -F &
Verify that zed updated the cache by making sure these are not empty:
cat /etc/zfs/zfs-list.cache/bpool
cat /etc/zfs/zfs-list.cache/rpool
Once the files have data, stop zed:
fg
Press Ctrl-C.
Fix the paths to eliminate /mnt:
sed -Ei "s /mnt/? / " /etc/zfs/zfs-list.cache/*
Snapshot initial install:
zfs snapshot bpool/BOOT/debian@install
zfs snapshot rpool/ROOT/debian@install
Exit chroot:
exit
Finalizing
One last sync was done in rescue mode:
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
Then we unmount all filesystems:
mount grep -v zfs tac awk '/\/mnt/ print $3 ' xargs -i umount -lf
zpool export -a
Reboot, swap the drives, and boot in ZFS. Hurray!
Benchmarks
This is a test that was ran in single-user mode using fio and the Ars
Technica recommended tests, which are:
- Single 4KiB random write process:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
- 16 parallel 64KiB random write processes:
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
- Single 1MiB random write process:
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O canmount=off \
-O compression=lz4 \
-O devices=off -O normalization=formD -O relatime=on -O xattr=sa \
-O mountpoint=/boot -R /mnt \
bpool /dev/sdc3
Main pool creation
This is a more typical pool creation.
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool /dev/sdc4
Breaking this down:
-o ashift=12: mentioned above, 4k sector size-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off-O canmount=off: do not make the pool mount automatically with
mount -a?-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now
Those settings are all available in zfsprops(8). Other flags are
defined in zpool-create(8). The reasoning behind them is also
explained in the upstream guide and some also in [the Debian
wiki][]. Those flags were actually not used:
-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.
[the Debian
wiki]: https://wiki.debian.org/ZFS#Advanced_Topics
Side note about single-disk pools
Also note that we're living dangerously here: single-disk ZFS pools
are rumoured to be more dangerous than not running ZFS at all. The
choice quote from this article is:
[...] any error can be detected, but cannot be corrected. This
sounds like an acceptable compromise, but its actually not. The
reason its not is that ZFS' metadata cannot be allowed to be
corrupted. If it is it is likely the zpool will be impossible to
mount (and will probably crash the system once the corruption is
found). So a couple of bad sectors in the right place will mean that
all data on the zpool will be lost. Not some, all. Also there's no
ZFS recovery tools, so you cannot recover any data on the drives.
Compared with (say) ext4, where a single disk error can recovered,
this is pretty bad. But we are ready to live with this with the idea
that we'll have hourly offline snapshots that we can easily recover
from. It's trade-off. Also, we're running this on a NVMe/M.2 drive
which typically just blinks out of existence completely, and doesn't
"bit rot" the way a HDD would.
Also, the FreeBSD handbook quick start doesn't have any warnings
about their first example, which is with a single disk. So I am
reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
- this creates two containers, for
ROOT and BOOT
zfs create -o canmount=off -o mountpoint=none rpool/ROOT &&
zfs create -o canmount=off -o mountpoint=none bpool/BOOT
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
- this creates the actual boot and root filesystems:
zfs create -o canmount=noauto -o mountpoint=/ rpool/ROOT/debian &&
zfs mount rpool/ROOT/debian &&
zfs create -o mountpoint=/boot bpool/BOOT/debian
I guess the debian name here is because we could technically have
multiple operating systems with the same underlying datasets.
- then the main datasets:
zfs create rpool/home &&
zfs create -o mountpoint=/root rpool/home/root &&
chmod 700 /mnt/root &&
zfs create rpool/var
- exclude temporary files from snapshots:
zfs create -o com.sun:auto-snapshot=false rpool/var/cache &&
zfs create -o com.sun:auto-snapshot=false rpool/var/tmp &&
chmod 1777 /mnt/var/tmp
- and skip automatic snapshots in Docker:
zfs create -o canmount=off rpool/var/lib &&
zfs create -o com.sun:auto-snapshot=false rpool/var/lib/docker
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
echo ' "storage-driver": "zfs" ' > /etc/docker/daemon.json
Note that podman has the same problem (and similar solution):
printf '[storage]\ndriver = "zfs"\n' > /etc/containers/storage.conf
- make a
tmpfs for /run:
mkdir /mnt/run &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
We don't create a /srv, as that's the HDD stuff.
Also mount the EFI partition:
mkfs.fat -F 32 /dev/sdc2 &&
mount /dev/sdc2 /mnt/boot/efi/
At this point, everything should be mounted in /mnt. It should look
like this:
root@curie:~# LANG=C df -h -t zfs -t vfat
Filesystem Size Used Avail Use% Mounted on
rpool/ROOT/debian 899G 384K 899G 1% /mnt
bpool/BOOT/debian 832M 123M 709M 15% /mnt/boot
rpool/home 899G 256K 899G 1% /mnt/home
rpool/home/root 899G 256K 899G 1% /mnt/root
rpool/var 899G 384K 899G 1% /mnt/var
rpool/var/cache 899G 256K 899G 1% /mnt/var/cache
rpool/var/tmp 899G 256K 899G 1% /mnt/var/tmp
rpool/var/lib/docker 899G 256K 899G 1% /mnt/var/lib/docker
/dev/sdc2 511M 4.0K 511M 1% /mnt/boot/efi
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
cat > /etc/systemd/system/zfs-import-bpool.service <<EOF
[Unit]
DefaultDependencies=no
Before=zfs-import-scan.service
Before=zfs-import-cache.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/sbin/zpool import -N -o cachefile=none bpool
# Work-around to preserve zpool cache:
ExecStartPre=-/bin/mv /etc/zfs/zpool.cache /etc/zfs/preboot_zpool.cache
ExecStartPost=-/bin/mv /etc/zfs/preboot_zpool.cache /etc/zfs/zpool.cache
[Install]
WantedBy=zfs-import.target
EOF
Enable the service:
systemctl enable zfs-import-bpool.service
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
ln -s /usr/share/systemd/tmp.mount /etc/systemd/system/ &&
systemctl enable tmp.mount
Rebuild boot loader with support for ZFS, but also to workaround
GRUB's missing zpool-features support:
grub-probe /boot grep -q zfs &&
update-initramfs -c -k all &&
sed -i 's,GRUB_CMDLINE_LINUX.*,GRUB_CMDLINE_LINUX="root=ZFS=rpool/ROOT/debian",' /etc/default/grub &&
update-grub
For good measure, make sure the right disk is configured here, for
example you might want to tag both drives in a RAID array:
dpkg-reconfigure grub-pc
Install grub to EFI while you're there:
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian --recheck --no-floppy
Filesystem mount ordering. The rationale here in the OpenZFS
guide is a little strange, but I don't dare ignore that.
mkdir /etc/zfs/zfs-list.cache
touch /etc/zfs/zfs-list.cache/bpool
touch /etc/zfs/zfs-list.cache/rpool
zed -F &
Verify that zed updated the cache by making sure these are not empty:
cat /etc/zfs/zfs-list.cache/bpool
cat /etc/zfs/zfs-list.cache/rpool
Once the files have data, stop zed:
fg
Press Ctrl-C.
Fix the paths to eliminate /mnt:
sed -Ei "s /mnt/? / " /etc/zfs/zfs-list.cache/*
Snapshot initial install:
zfs snapshot bpool/BOOT/debian@install
zfs snapshot rpool/ROOT/debian@install
Exit chroot:
exit
Finalizing
One last sync was done in rescue mode:
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
Then we unmount all filesystems:
mount grep -v zfs tac awk '/\/mnt/ print $3 ' xargs -i umount -lf
zpool export -a
Reboot, swap the drives, and boot in ZFS. Hurray!
Benchmarks
This is a test that was ran in single-user mode using fio and the Ars
Technica recommended tests, which are:
- Single 4KiB random write process:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
- 16 parallel 64KiB random write processes:
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
- Single 1MiB random write process:
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool /dev/sdc4
-o ashift=12: mentioned above, 4k sector size-O encryption=on -O keylocation=prompt -O keyformat=passphrase:
encryption, prompt for a password, default algorithm is
aes-256-gcm, explicit in the guide, made implicit here-O acltype=posixacl -O xattr=sa: enable ACLs, with better
performance (not enabled by default)-O dnodesize=auto: related to extended attributes, less
compatibility with other implementations-O compression=zstd: enable zstd compression, can be
disabled/enabled by dataset to with zfs set compression=off
rpool/example-O relatime=on: classic atime optimisation, another that could
be used on a busy server is atime=off-O canmount=off: do not make the pool mount automatically with
mount -a?-O mountpoint=/ -R /mnt: mount pool on / in the future, but
/mnt for now-O normalization=formD: normalize file names on comparisons (not
storage), implies utf8only=on, which is a bad idea (and
effectively meant my first sync failed to copy some files,
including this folder from a supysonic checkout). and this
cannot be changed after the filesystem is created. bad, bad, bad.[...] any error can be detected, but cannot be corrected. This sounds like an acceptable compromise, but its actually not. The reason its not is that ZFS' metadata cannot be allowed to be corrupted. If it is it is likely the zpool will be impossible to mount (and will probably crash the system once the corruption is found). So a couple of bad sectors in the right place will mean that all data on the zpool will be lost. Not some, all. Also there's no ZFS recovery tools, so you cannot recover any data on the drives.Compared with (say) ext4, where a single disk error can recovered, this is pretty bad. But we are ready to live with this with the idea that we'll have hourly offline snapshots that we can easily recover from. It's trade-off. Also, we're running this on a NVMe/M.2 drive which typically just blinks out of existence completely, and doesn't "bit rot" the way a HDD would. Also, the FreeBSD handbook quick start doesn't have any warnings about their first example, which is with a single disk. So I am reassured at least.
Creating mount points
Next we create the actual filesystems, known as "datasets" which are
the things that get mounted on mountpoint and hold the actual files.
- this creates two containers, for
ROOT and BOOT
zfs create -o canmount=off -o mountpoint=none rpool/ROOT &&
zfs create -o canmount=off -o mountpoint=none bpool/BOOT
Note that it's unclear to me why those datasets are necessary, but
they seem common practice, also used in this FreeBSD
example. The OpenZFS guide mentions the Solaris upgrades and
Ubuntu's zsys that use that container for upgrades and rollbacks.
This blog post seems to explain a bit the layout behind the
installer.
- this creates the actual boot and root filesystems:
zfs create -o canmount=noauto -o mountpoint=/ rpool/ROOT/debian &&
zfs mount rpool/ROOT/debian &&
zfs create -o mountpoint=/boot bpool/BOOT/debian
I guess the debian name here is because we could technically have
multiple operating systems with the same underlying datasets.
- then the main datasets:
zfs create rpool/home &&
zfs create -o mountpoint=/root rpool/home/root &&
chmod 700 /mnt/root &&
zfs create rpool/var
- exclude temporary files from snapshots:
zfs create -o com.sun:auto-snapshot=false rpool/var/cache &&
zfs create -o com.sun:auto-snapshot=false rpool/var/tmp &&
chmod 1777 /mnt/var/tmp
- and skip automatic snapshots in Docker:
zfs create -o canmount=off rpool/var/lib &&
zfs create -o com.sun:auto-snapshot=false rpool/var/lib/docker
Notice here a peculiarity: we must create rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
... and no, just creating /mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
echo ' "storage-driver": "zfs" ' > /etc/docker/daemon.json
Note that podman has the same problem (and similar solution):
printf '[storage]\ndriver = "zfs"\n' > /etc/containers/storage.conf
- make a
tmpfs for /run:
mkdir /mnt/run &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
We don't create a /srv, as that's the HDD stuff.
Also mount the EFI partition:
mkfs.fat -F 32 /dev/sdc2 &&
mount /dev/sdc2 /mnt/boot/efi/
At this point, everything should be mounted in /mnt. It should look
like this:
root@curie:~# LANG=C df -h -t zfs -t vfat
Filesystem Size Used Avail Use% Mounted on
rpool/ROOT/debian 899G 384K 899G 1% /mnt
bpool/BOOT/debian 832M 123M 709M 15% /mnt/boot
rpool/home 899G 256K 899G 1% /mnt/home
rpool/home/root 899G 256K 899G 1% /mnt/root
rpool/var 899G 384K 899G 1% /mnt/var
rpool/var/cache 899G 256K 899G 1% /mnt/var/cache
rpool/var/tmp 899G 256K 899G 1% /mnt/var/tmp
rpool/var/lib/docker 899G 256K 899G 1% /mnt/var/lib/docker
/dev/sdc2 511M 4.0K 511M 1% /mnt/boot/efi
Now that we have everything setup and mounted, let's copy all files
over.
Copying files
This is a list of all the mounted filesystems
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
You can check that the list is correct with:
mount -l -t ext4,btrfs,vfat awk ' print $3 '
Note that we skip /srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Note the failure to transfer that supysonic file? It turns out they
had a weird filename in their source tree, since then removed,
but still it showed how the utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
Also note the transfer speed: we seem capped at 76MB/s, or
608Mbit/s. This is not as fast as I was expecting: the USB connection
seems to be at around 5Gbps:
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
So it shouldn't cap at that speed. It's possible the USB adapter is
failing to give me the full speed though. It's not the M.2 SSD drive
either, as that has a ~500MB/s bandwidth, acccording to its spec.
At this point, we're about ready to do the final configuration. We
drop to single user mode and do the rest of the procedure. That used
to be shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
cat > /etc/systemd/system/zfs-import-bpool.service <<EOF
[Unit]
DefaultDependencies=no
Before=zfs-import-scan.service
Before=zfs-import-cache.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/sbin/zpool import -N -o cachefile=none bpool
# Work-around to preserve zpool cache:
ExecStartPre=-/bin/mv /etc/zfs/zpool.cache /etc/zfs/preboot_zpool.cache
ExecStartPost=-/bin/mv /etc/zfs/preboot_zpool.cache /etc/zfs/zpool.cache
[Install]
WantedBy=zfs-import.target
EOF
Enable the service:
systemctl enable zfs-import-bpool.service
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
ln -s /usr/share/systemd/tmp.mount /etc/systemd/system/ &&
systemctl enable tmp.mount
Rebuild boot loader with support for ZFS, but also to workaround
GRUB's missing zpool-features support:
grub-probe /boot grep -q zfs &&
update-initramfs -c -k all &&
sed -i 's,GRUB_CMDLINE_LINUX.*,GRUB_CMDLINE_LINUX="root=ZFS=rpool/ROOT/debian",' /etc/default/grub &&
update-grub
For good measure, make sure the right disk is configured here, for
example you might want to tag both drives in a RAID array:
dpkg-reconfigure grub-pc
Install grub to EFI while you're there:
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian --recheck --no-floppy
Filesystem mount ordering. The rationale here in the OpenZFS
guide is a little strange, but I don't dare ignore that.
mkdir /etc/zfs/zfs-list.cache
touch /etc/zfs/zfs-list.cache/bpool
touch /etc/zfs/zfs-list.cache/rpool
zed -F &
Verify that zed updated the cache by making sure these are not empty:
cat /etc/zfs/zfs-list.cache/bpool
cat /etc/zfs/zfs-list.cache/rpool
Once the files have data, stop zed:
fg
Press Ctrl-C.
Fix the paths to eliminate /mnt:
sed -Ei "s /mnt/? / " /etc/zfs/zfs-list.cache/*
Snapshot initial install:
zfs snapshot bpool/BOOT/debian@install
zfs snapshot rpool/ROOT/debian@install
Exit chroot:
exit
Finalizing
One last sync was done in rescue mode:
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
Then we unmount all filesystems:
mount grep -v zfs tac awk '/\/mnt/ print $3 ' xargs -i umount -lf
zpool export -a
Reboot, swap the drives, and boot in ZFS. Hurray!
Benchmarks
This is a test that was ran in single-user mode using fio and the Ars
Technica recommended tests, which are:
- Single 4KiB random write process:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
- 16 parallel 64KiB random write processes:
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
- Single 1MiB random write process:
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
ROOT and BOOT
zfs create -o canmount=off -o mountpoint=none rpool/ROOT &&
zfs create -o canmount=off -o mountpoint=none bpool/BOOT
zfs create -o canmount=noauto -o mountpoint=/ rpool/ROOT/debian &&
zfs mount rpool/ROOT/debian &&
zfs create -o mountpoint=/boot bpool/BOOT/debian
debian name here is because we could technically have
multiple operating systems with the same underlying datasets. zfs create rpool/home &&
zfs create -o mountpoint=/root rpool/home/root &&
chmod 700 /mnt/root &&
zfs create rpool/var
zfs create -o com.sun:auto-snapshot=false rpool/var/cache &&
zfs create -o com.sun:auto-snapshot=false rpool/var/tmp &&
chmod 1777 /mnt/var/tmp
zfs create -o canmount=off rpool/var/lib &&
zfs create -o com.sun:auto-snapshot=false rpool/var/lib/docker
rpool/var/lib to
create rpool/var/lib/docker otherwise we get this error:
cannot create 'rpool/var/lib/docker': parent does not exist
/mnt/var/lib doesn't fix that
problem. In fact, it makes things even more confusing because an
existing directory shadows a mountpoint, which is the opposite of
how things normally work.
Also note that you will probably need to change storage driver in
Docker, see the zfs-driver documentation for details but,
basically, I did:
echo ' "storage-driver": "zfs" ' > /etc/docker/daemon.json
printf '[storage]\ndriver = "zfs"\n' > /etc/containers/storage.conf
tmpfs for /run:
mkdir /mnt/run &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
mkfs.fat -F 32 /dev/sdc2 &&
mount /dev/sdc2 /mnt/boot/efi/
root@curie:~# LANG=C df -h -t zfs -t vfat
Filesystem Size Used Avail Use% Mounted on
rpool/ROOT/debian 899G 384K 899G 1% /mnt
bpool/BOOT/debian 832M 123M 709M 15% /mnt/boot
rpool/home 899G 256K 899G 1% /mnt/home
rpool/home/root 899G 256K 899G 1% /mnt/root
rpool/var 899G 384K 899G 1% /mnt/var
rpool/var/cache 899G 256K 899G 1% /mnt/var/cache
rpool/var/tmp 899G 256K 899G 1% /mnt/var/tmp
rpool/var/lib/docker 899G 256K 899G 1% /mnt/var/lib/docker
/dev/sdc2 511M 4.0K 511M 1% /mnt/boot/efi
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
mount -l -t ext4,btrfs,vfat awk ' print $3 '
/srv as it's on a different disk.
On the first run, we had:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
16,831,437 100% 184.14MB/s 0:00:00 (xfr#101, to-chk=0/110)
syncing / to /mnt/...
28,019,293,280 94% 47.63MB/s 0:09:21 (xfr#703710, ir-chk=6748/839220)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,267,990 98% 50.71MB/s 0:10:40 (xfr#736577, to-chk=0/867732)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
24,456,268,098 98% 68.03MB/s 0:05:42 (xfr#159867, ir-chk=6875/172377)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/B3AB0CDA9C4454B3C1197E5A22669DF8EE849D90"
199,762,528,125 93% 74.82MB/s 0:42:26 (xfr#1437846, ir-chk=1018/1983979)rsync: [generator] recv_generator: mkdir "/mnt/home/anarcat/dist/supysonic/tests/assets/\#346" failed: Invalid or incomplete multibyte or wide character (84)
*** Skipping any contents from this failed directory ***
315,384,723,978 96% 76.82MB/s 1:05:15 (xfr#2256473, to-chk=0/2993950)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
utf8only feature might not be such a bad
idea. At this point, the procedure was restarted all the way back to
"Creating pools", after unmounting all ZFS filesystems (umount
/mnt/run /mnt/boot/efi && umount -t zfs -a) and destroying the pool,
which, surprisingly, doesn't require any confirmation (zpool destroy
rpool).
The second run was cleaner:
root@curie:~# for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
syncing /boot/ to /mnt/boot/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/299)
syncing /boot/efi/ to /mnt/boot/efi/...
0 0% 0.00kB/s 0:00:00 (xfr#0, to-chk=0/110)
syncing / to /mnt/...
28,019,033,070 97% 42.03MB/s 0:10:35 (xfr#703671, ir-chk=1093/833515)rsync: [generator] delete_file: rmdir(var/lib/docker) failed: Device or resource busy (16)
could not make way for new symlink: var/lib/docker
34,081,807,102 98% 44.84MB/s 0:12:04 (xfr#736580, to-chk=0/867723)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
syncing /home/ to /mnt/home/...
rsync: [sender] readlink_stat("/home/anarcat/.fuse") failed: Permission denied (13)
IO error encountered -- skipping file deletion
24,043,086,450 96% 62.03MB/s 0:06:09 (xfr#151819, ir-chk=15117/172571)
file has vanished: "/home/anarcat/.cache/mozilla/firefox/s2hwvqbu.quantum/cache2/entries/4C1FDBFEA976FF924D062FB990B24B897A77B84B"
315,423,626,507 96% 67.09MB/s 1:14:43 (xfr#2256845, to-chk=0/2994364)
rsync error: some files/attrs were not transferred (see previous errors) (code 23) at main.c(1333) [sender=3.2.3]
anarcat@curie:~$ lsusb -tv head -4
/: Bus 02.Port 1: Dev 1, Class=root_hub, Driver=xhci_hcd/6p, 5000M
ID 1d6b:0003 Linux Foundation 3.0 root hub
__ Port 1: Dev 4, If 0, Class=Mass Storage, Driver=uas, 5000M
ID 0b05:1932 ASUSTek Computer, Inc.
shutdown now, but it seems like the systemd switch broke that,
so now you can reboot into grub and pick the "recovery"
option. Alternatively, you might try systemctl rescue, as I found
out.
I also wanted to copy the drive over to another new NVMe drive, but
that failed: it looks like the USB controller I have doesn't work with
older, non-NVME drives.
Boot configuration
Now we need to enter the new system to rebuild the boot loader and
initrd and so on.
First, we bind mounts and chroot into the ZFS disk:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
Next we add an extra service that imports the bpool on boot, to make
sure it survives a zpool.cache destruction:
cat > /etc/systemd/system/zfs-import-bpool.service <<EOF
[Unit]
DefaultDependencies=no
Before=zfs-import-scan.service
Before=zfs-import-cache.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/sbin/zpool import -N -o cachefile=none bpool
# Work-around to preserve zpool cache:
ExecStartPre=-/bin/mv /etc/zfs/zpool.cache /etc/zfs/preboot_zpool.cache
ExecStartPost=-/bin/mv /etc/zfs/preboot_zpool.cache /etc/zfs/zpool.cache
[Install]
WantedBy=zfs-import.target
EOF
Enable the service:
systemctl enable zfs-import-bpool.service
I had to trim down /etc/fstab and /etc/crypttab to only contain
references to the legacy filesystems (/srv is still BTRFS!).
If we don't already have a tmpfs defined in /etc/fstab:
ln -s /usr/share/systemd/tmp.mount /etc/systemd/system/ &&
systemctl enable tmp.mount
Rebuild boot loader with support for ZFS, but also to workaround
GRUB's missing zpool-features support:
grub-probe /boot grep -q zfs &&
update-initramfs -c -k all &&
sed -i 's,GRUB_CMDLINE_LINUX.*,GRUB_CMDLINE_LINUX="root=ZFS=rpool/ROOT/debian",' /etc/default/grub &&
update-grub
For good measure, make sure the right disk is configured here, for
example you might want to tag both drives in a RAID array:
dpkg-reconfigure grub-pc
Install grub to EFI while you're there:
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian --recheck --no-floppy
Filesystem mount ordering. The rationale here in the OpenZFS
guide is a little strange, but I don't dare ignore that.
mkdir /etc/zfs/zfs-list.cache
touch /etc/zfs/zfs-list.cache/bpool
touch /etc/zfs/zfs-list.cache/rpool
zed -F &
Verify that zed updated the cache by making sure these are not empty:
cat /etc/zfs/zfs-list.cache/bpool
cat /etc/zfs/zfs-list.cache/rpool
Once the files have data, stop zed:
fg
Press Ctrl-C.
Fix the paths to eliminate /mnt:
sed -Ei "s /mnt/? / " /etc/zfs/zfs-list.cache/*
Snapshot initial install:
zfs snapshot bpool/BOOT/debian@install
zfs snapshot rpool/ROOT/debian@install
Exit chroot:
exit
Finalizing
One last sync was done in rescue mode:
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
Then we unmount all filesystems:
mount grep -v zfs tac awk '/\/mnt/ print $3 ' xargs -i umount -lf
zpool export -a
Reboot, swap the drives, and boot in ZFS. Hurray!
Benchmarks
This is a test that was ran in single-user mode using fio and the Ars
Technica recommended tests, which are:
- Single 4KiB random write process:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
- 16 parallel 64KiB random write processes:
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
- Single 1MiB random write process:
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
mount --rbind /dev /mnt/dev &&
mount --rbind /proc /mnt/proc &&
mount --rbind /sys /mnt/sys &&
chroot /mnt /bin/bash
cat > /etc/systemd/system/zfs-import-bpool.service <<EOF
[Unit]
DefaultDependencies=no
Before=zfs-import-scan.service
Before=zfs-import-cache.service
[Service]
Type=oneshot
RemainAfterExit=yes
ExecStart=/sbin/zpool import -N -o cachefile=none bpool
# Work-around to preserve zpool cache:
ExecStartPre=-/bin/mv /etc/zfs/zpool.cache /etc/zfs/preboot_zpool.cache
ExecStartPost=-/bin/mv /etc/zfs/preboot_zpool.cache /etc/zfs/zpool.cache
[Install]
WantedBy=zfs-import.target
EOF
systemctl enable zfs-import-bpool.service
ln -s /usr/share/systemd/tmp.mount /etc/systemd/system/ &&
systemctl enable tmp.mount
grub-probe /boot grep -q zfs &&
update-initramfs -c -k all &&
sed -i 's,GRUB_CMDLINE_LINUX.*,GRUB_CMDLINE_LINUX="root=ZFS=rpool/ROOT/debian",' /etc/default/grub &&
update-grub
dpkg-reconfigure grub-pc
grub-install --target=x86_64-efi --efi-directory=/boot/efi --bootloader-id=debian --recheck --no-floppy
mkdir /etc/zfs/zfs-list.cache
touch /etc/zfs/zfs-list.cache/bpool
touch /etc/zfs/zfs-list.cache/rpool
zed -F &
cat /etc/zfs/zfs-list.cache/bpool
cat /etc/zfs/zfs-list.cache/rpool
fg
Press Ctrl-C.
sed -Ei "s /mnt/? / " /etc/zfs/zfs-list.cache/*
zfs snapshot bpool/BOOT/debian@install
zfs snapshot rpool/ROOT/debian@install
exit
for fs in /boot/ /boot/efi/ / /home/; do
echo "syncing $fs to /mnt$fs..." &&
rsync -aSHAXx --info=progress2 --delete $fs /mnt$fs
done
mount grep -v zfs tac awk '/\/mnt/ print $3 ' xargs -i umount -lf
zpool export -a
Benchmarks
This is a test that was ran in single-user mode using fio and the Ars
Technica recommended tests, which are:
- Single 4KiB random write process:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
- 16 parallel 64KiB random write processes:
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
- Single 1MiB random write process:
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Strangely, that's not exactly what the author, Jim Salter, did in
his actual test bench used in the ZFS benchmarking
article. The first thing is there's no read test at all, which is
already pretty strange. But also it doesn't include stuff like
dropping caches or repeating results.
So here's my variation, which i called fio-ars-bench.sh for
now. It just batches a bunch of fio tests, one by one, 60 seconds
each. It should take about 12 minutes to run, as there are 3 pair of
tests, read/write, with and without async.
My bias, before building, running and analysing those results is that
ZFS should outperform the traditional stack on writes, but possibly
not on reads. It's also possible it outperforms it on both, because
it's a newer drive. A new test might be possible with a new external
USB drive as well, although I doubt I will find the time to do this.
Results
All tests were done on WD blue SN550 drives, which claims to be
able to push 2400MB/s read and 1750MB/s write. An extra drive was
bought to move the LVM setup from a WDC WDS500G1B0B-00AS40 SSD, a WD
blue M.2 2280 SSD that was at least 5 years old, spec'd at 560MB/s
read, 530MB/s write. Benchmarks were done on the M.2 SSD drive but
discarded so that the drive difference is not a factor in the test.
In practice, I'm going to assume we'll never reach those numbers
because we're not actually NVMe (this is an old workstation!) so the
bottleneck isn't the disk itself. For our purposes, it might still
give us useful results.
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
fio --name=randwrite4k1x --ioengine=posixaio --rw=randwrite --bs=4k --size=4g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
fio --name=randwrite64k16x --ioengine=posixaio --rw=randwrite --bs=64k --size=256m --numjobs=16 --iodepth=16 --runtime=60 --time_based --end_fsync=1
fio --name=randwrite1m1x --ioengine=posixaio --rw=randwrite --bs=1m --size=16g --numjobs=1 --iodepth=1 --runtime=60 --time_based --end_fsync=1
Rescue test, LUKS/LVM/ext4
Those tests were performed with everything shutdown, after either
entering the system in rescue mode, or by reaching that target with:
systemctl rescue
The network might have been started before or after the test as well:
systemctl start systemd-networkd
So it should be fairly reliable as basically nothing else is running.
Raw numbers, from the ?job-curie-lvm.log, converted to MiB/s and
manually merged:
systemctl rescue
systemctl start systemd-networkd
| test | read I/O | read IOPS | write I/O | write IOPS |
|---|---|---|---|---|
| rand4k4g1x | 39.27 | 10052 | 212.15 | 54310 |
| rand4k4g1x--fsync=1 | 39.29 | 10057 | 2.73 | 699 |
| rand64k256m16x | 1297.00 | 20751 | 1068.57 | 17097 |
| rand64k256m16x--fsync=1 | 1290.90 | 20654 | 353.82 | 5661 |
| rand1m16g1x | 315.15 | 315 | 563.77 | 563 |
| rand1m16g1x--fsync=1 | 345.88 | 345 | 157.01 | 157 |
Rescue test, ZFS This test was also performed in rescue mode. Raw numbers, from the ?job-curie-zfs.log, converted to MiB/s and manually merged:
| test | read I/O | read IOPS | write I/O | write IOPS |
|---|---|---|---|---|
| rand4k4g1x | 77.20 | 19763 | 27.13 | 6944 |
| rand4k4g1x--fsync=1 | 76.16 | 19495 | 6.53 | 1673 |
| rand64k256m16x | 1882.40 | 30118 | 70.58 | 1129 |
| rand64k256m16x--fsync=1 | 1865.13 | 29842 | 71.98 | 1151 |
| rand1m16g1x | 921.62 | 921 | 102.21 | 102 |
| rand1m16g1x--fsync=1 | 908.37 | 908 | 64.30 | 64 |
Conclusions
Really, ZFS has trouble performing in all write conditions. The
random 4k sync write test is the only place where ZFS outperforms
LVM in writes, and barely (7MiB/s vs 3MiB/s). Everywhere else, writes
are much slower, sometimes by an order of magnitude.
And before some ZFS zealot jumps in talking about the SLOG or some
other cache that could be added to improved performance, I'll remind
you that those numbers are on a bare bones NVMe drive, pretty much as
fast storage as you can find on this machine. Adding another NVMe
drive as a cache probably will not improve write performance here.
Still, those are very different results than the tests performed by
Salter which shows ZFS beating traditional configurations in all
categories but uncached 4k reads (not writes!). That said, those tests
are very different from the tests I performed here, where I test
writes on a single disk, not a RAID array, which might explain the
discrepancy.
Also, note that neither LVM or ZFS manage to reach the 2400MB/s read
and 1750MB/s write performance specification. ZFS does manage to reach
82% of the read performance (1973MB/s) and LVM 64% of the write
performance (1120MB/s). LVM hits 57% of the read performance and ZFS
hits barely 6% of the write performance.
Overall, I'm a bit disappointed in the ZFS write performance here, I
must say. Maybe I need to tweak the record size or some other ZFS
voodoo, but I'll note that I didn't have to do any such configuration
on the other side to kick ZFS in the pants...
Real world experience
This section document not synthetic backups, but actual real world
workloads, comparing before and after I switched my workstation to
ZFS.
Docker performance
I had the feeling that running some git hook (which was firing a
Docker container) was "slower" somehow. It seems that, at runtime, ZFS
backends are significant slower than their overlayfs/ext4 equivalent:
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:53 curie dockerd[1723]: time="2022-05-16T14:42:53.087219426-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 pid=151170
May 16 14:42:53 curie systemd[1]: Started libcontainer container af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.
May 16 14:42:54 curie systemd[1]: docker-af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.scope: Succeeded.
May 16 14:42:54 curie dockerd[1723]: time="2022-05-16T14:42:54.047297800-04:00" level=info msg="shim disconnected" id=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10
May 16 14:42:54 curie dockerd[998]: time="2022-05-16T14:42:54.051365015-04:00" level=info msg="ignoring event" container=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 16 14:42:54 curie systemd[2444]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[2444]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
Translating this:
- container setup: ~1 second
- container runtime: ~1 second
- container teardown: ~1 second
- total runtime: 2-3 seconds
Obviously, those timestamps are not quite accurate enough to make
precise measurements...
After I switched to ZFS:
mai 30 15:31:39 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:39 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:40 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:40 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:41 curie dockerd[3199]: time="2022-05-30T15:31:41.551403693-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 pid=141080
mai 30 15:31:41 curie systemd[1]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[5287]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[1]: Started libcontainer container 42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.
mai 30 15:31:45 curie systemd[1]: docker-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.scope: Succeeded.
mai 30 15:31:45 curie dockerd[3199]: time="2022-05-30T15:31:45.883019128-04:00" level=info msg="shim disconnected" id=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142
mai 30 15:31:45 curie dockerd[1726]: time="2022-05-30T15:31:45.883064491-04:00" level=info msg="ignoring event" container=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
mai 30 15:31:45 curie systemd[1]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
That's double or triple the run time, from 2 seconds to 6
seconds. Most of the time is spent in run time, inside the
container. Here's the breakdown:
- container setup: ~2 seconds
- container run: ~4 seconds
- container teardown: ~1 second
- total run time: about ~6-7 seconds
That's a two- to three-fold increase! Clearly something is going on
here that I should tweak. It's possible that code path is less
optimized in Docker. I also worry about podman, but apparently it
also supports ZFS backends. Possibly it would perform better, but
at this stage I wouldn't have a good comparison: maybe it would have
performed better on non-ZFS as well...
Interactivity
While doing the offsite backups (below), the system became somewhat
"sluggish". I felt everything was slow, and I estimate it introduced
~50ms latency in any input device.
Arguably, those are all USB and the external drive was connected
through USB, but I suspect the ZFS drivers are not as well tuned with
the scheduler as the regular filesystem drivers...
Recovery procedures
For test purposes, I unmounted all systems during the procedure:
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
And disconnected the drive, to see how I would recover this system
from another Linux system in case of a total motherboard failure.
To import an existing pool, plug the device, then import the pool with
an alternate root, so it doesn't mount over your existing filesystems,
then you mount the root filesystem and all the others:
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Offsite backup
Part of the goal of using ZFS is to simplify and harden backups. I
wanted to experiment with shorter recovery times specifically both
point in time recovery objective and recovery time objective
and faster incremental backups.
This is, therefore, part of my backup services.
This section documents how an external NVMe enclosure was setup in a
pool to mirror the datasets from my workstation.
The final setup should include syncoid copying datasets to the backup
server regularly, but I haven't finished that configuration yet.
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
sfdisk -d /dev/nvme0n1 sfdisk --no-reread /dev/sda --force
Pool creation
This is similar to the main pool creation, except we tweaked a few
bits after changing the upstream procedure:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O xattr=sa \
-O compression=lz4 \
-O devices=off \
-O relatime=on \
-O canmount=off \
-O mountpoint=/boot -R /mnt \
bpool-tubman /dev/sdb3
The change from the main boot pool are:
- no unicode normalization
- different device path (
sdb used to be the M.2 device, it's now
nvme0n1)
- reordered parameters
Main pool creation is:
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool-tubman /dev/sdb4
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
zpool export bpool-tubman
zpool export rpool-tubman
Raw disk benchmark
Copied the 512GB SSD/M.2 device to another 1024GB NVMe/M.2 device:
anarcat@curie:~$ sudo dd if=/dev/sdb of=/dev/sdc bs=4M status=progress conv=fdatasync
499944259584 octets (500 GB, 466 GiB) copi s, 1713 s, 292 MB/s
119235+1 enregistrements lus
119235+1 enregistrements crits
500107862016 octets (500 GB, 466 GiB) copi s, 1719,93 s, 291 MB/s
... while both over USB, whoohoo 300MB/s!
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcos v1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Some more SMART stats:
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
Docker performance
I had the feeling that running some git hook (which was firing a
Docker container) was "slower" somehow. It seems that, at runtime, ZFS
backends are significant slower than their overlayfs/ext4 equivalent:
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:53 curie dockerd[1723]: time="2022-05-16T14:42:53.087219426-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 pid=151170
May 16 14:42:53 curie systemd[1]: Started libcontainer container af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.
May 16 14:42:54 curie systemd[1]: docker-af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.scope: Succeeded.
May 16 14:42:54 curie dockerd[1723]: time="2022-05-16T14:42:54.047297800-04:00" level=info msg="shim disconnected" id=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10
May 16 14:42:54 curie dockerd[998]: time="2022-05-16T14:42:54.051365015-04:00" level=info msg="ignoring event" container=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 16 14:42:54 curie systemd[2444]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[2444]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
Translating this:
- container setup: ~1 second
- container runtime: ~1 second
- container teardown: ~1 second
- total runtime: 2-3 seconds
Obviously, those timestamps are not quite accurate enough to make
precise measurements...
After I switched to ZFS:
mai 30 15:31:39 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:39 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:40 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:40 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:41 curie dockerd[3199]: time="2022-05-30T15:31:41.551403693-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 pid=141080
mai 30 15:31:41 curie systemd[1]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[5287]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[1]: Started libcontainer container 42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.
mai 30 15:31:45 curie systemd[1]: docker-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.scope: Succeeded.
mai 30 15:31:45 curie dockerd[3199]: time="2022-05-30T15:31:45.883019128-04:00" level=info msg="shim disconnected" id=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142
mai 30 15:31:45 curie dockerd[1726]: time="2022-05-30T15:31:45.883064491-04:00" level=info msg="ignoring event" container=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
mai 30 15:31:45 curie systemd[1]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
That's double or triple the run time, from 2 seconds to 6
seconds. Most of the time is spent in run time, inside the
container. Here's the breakdown:
- container setup: ~2 seconds
- container run: ~4 seconds
- container teardown: ~1 second
- total run time: about ~6-7 seconds
That's a two- to three-fold increase! Clearly something is going on
here that I should tweak. It's possible that code path is less
optimized in Docker. I also worry about podman, but apparently it
also supports ZFS backends. Possibly it would perform better, but
at this stage I wouldn't have a good comparison: maybe it would have
performed better on non-ZFS as well...
Interactivity
While doing the offsite backups (below), the system became somewhat
"sluggish". I felt everything was slow, and I estimate it introduced
~50ms latency in any input device.
Arguably, those are all USB and the external drive was connected
through USB, but I suspect the ZFS drivers are not as well tuned with
the scheduler as the regular filesystem drivers...
Recovery procedures
For test purposes, I unmounted all systems during the procedure:
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
And disconnected the drive, to see how I would recover this system
from another Linux system in case of a total motherboard failure.
To import an existing pool, plug the device, then import the pool with
an alternate root, so it doesn't mount over your existing filesystems,
then you mount the root filesystem and all the others:
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Offsite backup
Part of the goal of using ZFS is to simplify and harden backups. I
wanted to experiment with shorter recovery times specifically both
point in time recovery objective and recovery time objective
and faster incremental backups.
This is, therefore, part of my backup services.
This section documents how an external NVMe enclosure was setup in a
pool to mirror the datasets from my workstation.
The final setup should include syncoid copying datasets to the backup
server regularly, but I haven't finished that configuration yet.
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
sfdisk -d /dev/nvme0n1 sfdisk --no-reread /dev/sda --force
Pool creation
This is similar to the main pool creation, except we tweaked a few
bits after changing the upstream procedure:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O xattr=sa \
-O compression=lz4 \
-O devices=off \
-O relatime=on \
-O canmount=off \
-O mountpoint=/boot -R /mnt \
bpool-tubman /dev/sdb3
The change from the main boot pool are:
- no unicode normalization
- different device path (
sdb used to be the M.2 device, it's now
nvme0n1)
- reordered parameters
Main pool creation is:
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool-tubman /dev/sdb4
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
zpool export bpool-tubman
zpool export rpool-tubman
Raw disk benchmark
Copied the 512GB SSD/M.2 device to another 1024GB NVMe/M.2 device:
anarcat@curie:~$ sudo dd if=/dev/sdb of=/dev/sdc bs=4M status=progress conv=fdatasync
499944259584 octets (500 GB, 466 GiB) copi s, 1713 s, 292 MB/s
119235+1 enregistrements lus
119235+1 enregistrements crits
500107862016 octets (500 GB, 466 GiB) copi s, 1719,93 s, 291 MB/s
... while both over USB, whoohoo 300MB/s!
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcos v1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Some more SMART stats:
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87\x2dinit-merged.mount: Succeeded.
May 16 14:42:52 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:53 curie dockerd[1723]: time="2022-05-16T14:42:53.087219426-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 pid=151170
May 16 14:42:53 curie systemd[1]: Started libcontainer container af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.
May 16 14:42:54 curie systemd[1]: docker-af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10.scope: Succeeded.
May 16 14:42:54 curie dockerd[1723]: time="2022-05-16T14:42:54.047297800-04:00" level=info msg="shim disconnected" id=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10
May 16 14:42:54 curie dockerd[998]: time="2022-05-16T14:42:54.051365015-04:00" level=info msg="ignoring event" container=af22586fba07014a4d10ab19da10cf280db7a43cad804d6c1e9f2682f12b5f10 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
May 16 14:42:54 curie systemd[2444]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[2444]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[5161]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: run-docker-netns-f5453c87c879.mount: Succeeded.
May 16 14:42:54 curie systemd[1]: home-docker-overlay2-17e4d24228decc2d2d493efc401dbfb7ac29739da0e46775e122078d9daf3e87-merged.mount: Succeeded.
mai 30 15:31:39 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:39 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf\x2dinit.mount: Succeeded.
mai 30 15:31:40 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:40 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:41 curie dockerd[3199]: time="2022-05-30T15:31:41.551403693-04:00" level=info msg="starting signal loop" namespace=moby path=/run/docker/containerd/daemon/io.containerd.runtime.v2.task/moby/42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 pid=141080
mai 30 15:31:41 curie systemd[1]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[5287]: run-docker-runtime\x2drunc-moby-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142-runc.ZVcjvl.mount: Succeeded.
mai 30 15:31:41 curie systemd[1]: Started libcontainer container 42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.
mai 30 15:31:45 curie systemd[1]: docker-42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142.scope: Succeeded.
mai 30 15:31:45 curie dockerd[3199]: time="2022-05-30T15:31:45.883019128-04:00" level=info msg="shim disconnected" id=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142
mai 30 15:31:45 curie dockerd[1726]: time="2022-05-30T15:31:45.883064491-04:00" level=info msg="ignoring event" container=42a1a1ed5912a7227148e997f442e7ab2e5cc3558aa3471548223c5888c9b142 module=libcontainerd namespace=moby topic=/tasks/delete type="*events.TaskDelete"
mai 30 15:31:45 curie systemd[1]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: run-docker-netns-e45f5cf5f465.mount: Succeeded.
mai 30 15:31:45 curie systemd[1]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
mai 30 15:31:45 curie systemd[5287]: var-lib-docker-zfs-graph-41ce08fb7a1d3a9c101694b82722f5621c0b4819bd1d9f070933fd1e00543cdf.mount: Succeeded.
Recovery procedures
For test purposes, I unmounted all systems during the procedure:
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
And disconnected the drive, to see how I would recover this system
from another Linux system in case of a total motherboard failure.
To import an existing pool, plug the device, then import the pool with
an alternate root, so it doesn't mount over your existing filesystems,
then you mount the root filesystem and all the others:
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Offsite backup
Part of the goal of using ZFS is to simplify and harden backups. I
wanted to experiment with shorter recovery times specifically both
point in time recovery objective and recovery time objective
and faster incremental backups.
This is, therefore, part of my backup services.
This section documents how an external NVMe enclosure was setup in a
pool to mirror the datasets from my workstation.
The final setup should include syncoid copying datasets to the backup
server regularly, but I haven't finished that configuration yet.
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
sfdisk -d /dev/nvme0n1 sfdisk --no-reread /dev/sda --force
Pool creation
This is similar to the main pool creation, except we tweaked a few
bits after changing the upstream procedure:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O xattr=sa \
-O compression=lz4 \
-O devices=off \
-O relatime=on \
-O canmount=off \
-O mountpoint=/boot -R /mnt \
bpool-tubman /dev/sdb3
The change from the main boot pool are:
- no unicode normalization
- different device path (
sdb used to be the M.2 device, it's now
nvme0n1)
- reordered parameters
Main pool creation is:
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool-tubman /dev/sdb4
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
zpool export bpool-tubman
zpool export rpool-tubman
Raw disk benchmark
Copied the 512GB SSD/M.2 device to another 1024GB NVMe/M.2 device:
anarcat@curie:~$ sudo dd if=/dev/sdb of=/dev/sdc bs=4M status=progress conv=fdatasync
499944259584 octets (500 GB, 466 GiB) copi s, 1713 s, 292 MB/s
119235+1 enregistrements lus
119235+1 enregistrements crits
500107862016 octets (500 GB, 466 GiB) copi s, 1719,93 s, 291 MB/s
... while both over USB, whoohoo 300MB/s!
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcos v1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Some more SMART stats:
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
umount /mnt/boot/efi /mnt/boot/run
umount -a -t zfs
zpool export -a
zpool import -l -a -R /mnt &&
zfs mount rpool/ROOT/debian &&
zfs mount -a &&
mount /dev/sdc2 /mnt/boot/efi &&
mount -t tmpfs tmpfs /mnt/run &&
mkdir /mnt/run/lock
Partitioning
The above partitioning procedure used sgdisk, but I couldn't figure
out how to do this with sgdisk, so this uses sfdisk to dump the
partition from the first disk to an external, identical drive:
sfdisk -d /dev/nvme0n1 sfdisk --no-reread /dev/sda --force
Pool creation
This is similar to the main pool creation, except we tweaked a few
bits after changing the upstream procedure:
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O xattr=sa \
-O compression=lz4 \
-O devices=off \
-O relatime=on \
-O canmount=off \
-O mountpoint=/boot -R /mnt \
bpool-tubman /dev/sdb3
The change from the main boot pool are:
- no unicode normalization
- different device path (
sdb used to be the M.2 device, it's now
nvme0n1)
- reordered parameters
Main pool creation is:
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool-tubman /dev/sdb4
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
zpool export bpool-tubman
zpool export rpool-tubman
Raw disk benchmark
Copied the 512GB SSD/M.2 device to another 1024GB NVMe/M.2 device:
anarcat@curie:~$ sudo dd if=/dev/sdb of=/dev/sdc bs=4M status=progress conv=fdatasync
499944259584 octets (500 GB, 466 GiB) copi s, 1713 s, 292 MB/s
119235+1 enregistrements lus
119235+1 enregistrements crits
500107862016 octets (500 GB, 466 GiB) copi s, 1719,93 s, 291 MB/s
... while both over USB, whoohoo 300MB/s!
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcos v1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Some more SMART stats:
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
sfdisk -d /dev/nvme0n1 sfdisk --no-reread /dev/sda --force
zpool create \
-o cachefile=/etc/zfs/zpool.cache \
-o ashift=12 -d \
-o feature@async_destroy=enabled \
-o feature@bookmarks=enabled \
-o feature@embedded_data=enabled \
-o feature@empty_bpobj=enabled \
-o feature@enabled_txg=enabled \
-o feature@extensible_dataset=enabled \
-o feature@filesystem_limits=enabled \
-o feature@hole_birth=enabled \
-o feature@large_blocks=enabled \
-o feature@lz4_compress=enabled \
-o feature@spacemap_histogram=enabled \
-o feature@zpool_checkpoint=enabled \
-O acltype=posixacl -O xattr=sa \
-O compression=lz4 \
-O devices=off \
-O relatime=on \
-O canmount=off \
-O mountpoint=/boot -R /mnt \
bpool-tubman /dev/sdb3
- no unicode normalization
- different device path (
sdbused to be the M.2 device, it's nownvme0n1) - reordered parameters
zpool create \
-o ashift=12 \
-O encryption=on -O keylocation=prompt -O keyformat=passphrase \
-O acltype=posixacl -O xattr=sa -O dnodesize=auto \
-O compression=zstd \
-O relatime=on \
-O canmount=off \
-O mountpoint=/ -R /mnt \
rpool-tubman /dev/sdb4
First sync
I used syncoid to copy all pools over to the external device. syncoid
is a thing that's part of the sanoid project which is
specifically designed to sync snapshots between pool, typically over
SSH links but it can also operate locally.
The sanoid command had a --readonly argument to simulate changes,
but syncoid didn't so I tried to fix that with an upstream PR.
It seems it would be better to do this by hand, but this was much
easier. The full first sync was:
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
Funny how the CRITICAL ERROR doesn't actually stop syncoid and it
just carries on merrily doing when it's telling you it's "cowardly
refusing to destroy your existing target"... Maybe that's because my pull
request broke something though...
During the transfer, the computer was very sluggish: everything feels
like it has ~30-50ms latency extra:
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
I wonder how much of that is due to syncoid, particularly because I
often saw mbuffer and pv in there which are not strictly necessary
to do those kind of operations, as far as I understand.
Once that's done, export the pools to disconnect the drive:
zpool export bpool-tubman
zpool export rpool-tubman
Raw disk benchmark
Copied the 512GB SSD/M.2 device to another 1024GB NVMe/M.2 device:
anarcat@curie:~$ sudo dd if=/dev/sdb of=/dev/sdc bs=4M status=progress conv=fdatasync
499944259584 octets (500 GB, 466 GiB) copi s, 1713 s, 292 MB/s
119235+1 enregistrements lus
119235+1 enregistrements crits
500107862016 octets (500 GB, 466 GiB) copi s, 1719,93 s, 291 MB/s
... while both over USB, whoohoo 300MB/s!
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcos v1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Some more SMART stats:
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
root@curie:/home/anarcat# ./bin/syncoid -r bpool bpool-tubman
CRITICAL ERROR: Target bpool-tubman exists but has no snapshots matching with bpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target bpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create bpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot bpool/BOOT@test (~ 42 KB) to new target filesystem:
44.2KiB 0:00:00 [4.19MiB/s] [========================================================================================================================] 103%
INFO: Updating new target filesystem with incremental bpool/BOOT@test ... syncoid_curie_2022-05-30:12:50:39 (~ 4 KB):
2.13KiB 0:00:00 [ 114KiB/s] [===============================================================> ] 53%
INFO: Sending oldest full snapshot bpool/BOOT/debian@install (~ 126.0 MB) to new target filesystem:
126MiB 0:00:00 [ 308MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental bpool/BOOT/debian@install ... syncoid_curie_2022-05-30:12:50:39 (~ 113.4 MB):
113MiB 0:00:00 [ 315MiB/s] [=======================================================================================================================>] 100%
root@curie:/home/anarcat# ./bin/syncoid -r rpool rpool-tubman
CRITICAL ERROR: Target rpool-tubman exists but has no snapshots matching with rpool!
Replication to target would require destroying existing
target. Cowardly refusing to destroy your existing target.
NOTE: Target rpool-tubman dataset is < 64MB used - did you mistakenly run
zfs create rpool-tubman on the target? ZFS initial
replication must be to a NON EXISTENT DATASET, which will
then be CREATED BY the initial replication process.
INFO: Sending oldest full snapshot rpool/ROOT@syncoid_curie_2022-05-30:12:50:51 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [2.44MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/ROOT/debian@install (~ 25.9 GB) to new target filesystem:
25.9GiB 0:03:33 [ 124MiB/s] [=======================================================================================================================>] 100%
INFO: Updating new target filesystem with incremental rpool/ROOT/debian@install ... syncoid_curie_2022-05-30:12:50:52 (~ 3.9 GB):
3.92GiB 0:00:33 [ 119MiB/s] [======================================================================================================================> ] 99%
INFO: Sending oldest full snapshot rpool/home@syncoid_curie_2022-05-30:12:55:04 (~ 276.8 GB) to new target filesystem:
277GiB 0:27:13 [ 174MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/home/root@syncoid_curie_2022-05-30:13:22:19 (~ 2.2 GB) to new target filesystem:
2.22GiB 0:00:25 [90.2MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var@syncoid_curie_2022-05-30:13:22:47 (~ 5.6 GB) to new target filesystem:
5.56GiB 0:00:32 [ 176MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/cache@syncoid_curie_2022-05-30:13:23:22 (~ 627.3 MB) to new target filesystem:
627MiB 0:00:03 [ 169MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib@syncoid_curie_2022-05-30:13:23:28 (~ 69 KB) to new target filesystem:
44.2KiB 0:00:00 [1.40MiB/s] [===========================================================================> ] 63%
INFO: Sending oldest full snapshot rpool/var/lib/docker@syncoid_curie_2022-05-30:13:23:28 (~ 442.6 MB) to new target filesystem:
443MiB 0:00:04 [ 103MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 (~ 6.3 MB) to new target filesystem:
6.49MiB 0:00:00 [12.9MiB/s] [========================================================================================================================] 102%
INFO: Updating new target filesystem with incremental rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254 ... syncoid_curie_2022-05-30:13:23:34 (~ 4 KB):
1.52KiB 0:00:00 [27.6KiB/s] [============================================> ] 38%
INFO: Sending oldest full snapshot rpool/var/lib/flatpak@syncoid_curie_2022-05-30:13:23:36 (~ 2.0 GB) to new target filesystem:
2.00GiB 0:00:17 [ 115MiB/s] [=======================================================================================================================>] 100%
INFO: Sending oldest full snapshot rpool/var/tmp@syncoid_curie_2022-05-30:13:23:55 (~ 57.0 MB) to new target filesystem:
61.8MiB 0:00:01 [45.0MiB/s] [========================================================================================================================] 108%
INFO: Clone is recreated on target rpool-tubman/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205 based on rpool/var/lib/docker/05c0de7fabbea60500eaa495d0d82038249f6faa63b12914737c4d71520e62c5@266253254
INFO: Sending oldest full snapshot rpool/var/lib/docker/ed71ddd563a779ba6fb37b3b1d0cc2c11eca9b594e77b4b234867ebcb162b205@syncoid_curie_2022-05-30:13:23:58 (~ 218.6 MB) to new target filesystem:
219MiB 0:00:01 [ 151MiB/s] [=======================================================================================================================>] 100%
anarcat@curie:sanoid$ LANG=C top -b -n 1 head -20
top - 13:07:05 up 6 days, 4:01, 1 user, load average: 16.13, 16.55, 11.83
Tasks: 606 total, 6 running, 598 sleeping, 0 stopped, 2 zombie
%Cpu(s): 18.8 us, 72.5 sy, 1.2 ni, 5.0 id, 1.2 wa, 0.0 hi, 1.2 si, 0.0 st
MiB Mem : 15898.4 total, 1387.6 free, 13170.0 used, 1340.8 buff/cache
MiB Swap: 0.0 total, 0.0 free, 0.0 used. 1319.8 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
70 root 20 0 0 0 0 S 83.3 0.0 6:12.67 kswapd0
4024878 root 20 0 282644 96432 10288 S 44.4 0.6 0:11.43 puppet
3896136 root 20 0 35328 16528 48 S 22.2 0.1 2:08.04 mbuffer
3896135 root 20 0 10328 776 168 R 16.7 0.0 1:22.93 zfs
3896138 root 20 0 10588 788 156 R 16.7 0.0 1:49.30 zfs
350 root 0 -20 0 0 0 R 11.1 0.0 1:03.53 z_rd_int
351 root 0 -20 0 0 0 S 11.1 0.0 1:04.15 z_rd_int
3896137 root 20 0 4384 352 244 R 11.1 0.0 0:44.73 pv
4034094 anarcat 30 10 20028 13960 2428 S 11.1 0.1 0:00.70 mbsync
4036539 anarcat 20 0 9604 3464 2408 R 11.1 0.0 0:00.04 top
352 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
353 root 0 -20 0 0 0 S 5.6 0.0 1:03.64 z_rd_int
354 root 0 -20 0 0 0 S 5.6 0.0 1:04.01 z_rd_int
zpool export bpool-tubman
zpool export rpool-tubman
anarcat@curie:~$ sudo dd if=/dev/sdb of=/dev/sdc bs=4M status=progress conv=fdatasync
499944259584 octets (500 GB, 466 GiB) copi s, 1713 s, 292 MB/s
119235+1 enregistrements lus
119235+1 enregistrements crits
500107862016 octets (500 GB, 466 GiB) copi s, 1719,93 s, 291 MB/s
Monitoring
ZFS should be monitoring your pools regularly. Normally, the [[!debman
zed]] daemon monitors all ZFS events. It is the thing that will report
when a scrub failed, for example. See this configuration guide.
Scrubs should be regularly scheduled to ensure consistency of the
pool. This can be done in newer zfsutils-linux versions
(bullseye-backports or bookworm) with one of those, depending on the
desired frequency:
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
When the scrub runs, if it finds anything it will send an event which
will get picked up by the zed daemon which will then send a
notification, see below for an example.
TODO: deploy on curie, if possible (probably not because no RAID)
TODO: this should be in Puppet
Scrub warning example
So what happens when problems are found? Here's an example of how I
dealt with an error I received.
After setting up another server (tubman) with ZFS, I
eventually ended up getting a warning from the ZFS toolchain.
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
This, in itself, is a little worrisome. But it helpfully links to this
more detailed documentation (and props up there: the link still
works) which explains this is a "minor" problem (something that could
be included in the report).
In this case, this happened on a server setup on 2021-04-28, but the
disks and server hardware are much older. The server itself
(marcos v1) was built
around 2011, over 10 years ago now. The hard drive in question is:
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
Some more SMART stats:
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
That's over a year of power on, which shouldn't be so bad. It has
written about 10TB of data (21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
It has seen much more reads than the other disk which is also interesting:
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
That's 4 years of Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
systemctl enable zfs-scrub-weekly@rpool.timer --now
systemctl enable zfs-scrub-monthly@rpool.timer --now
Date: Sun, 09 Oct 2022 00:58:08 -0400
From: root <root@anarc.at>
To: root@anarc.at
Subject: ZFS scrub_finish event for rpool on tubman
ZFS has finished a scrub:
eid: 39536
class: scrub_finish
host: tubman
time: 2022-10-09 00:58:07-0400
pool: rpool
state: ONLINE
status: One or more devices has experienced an unrecoverable error. An
attempt was made to correct the error. Applications are unaffected.
action: Determine if the device needs to be replaced, and clear the errors
using 'zpool clear' or replace the device with 'zpool replace'.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-9P
scan: scrub repaired 0B in 00:33:57 with 0 errors on Sun Oct 9 00:58:07 2022
config:
NAME STATE READ WRITE CKSUM
rpool ONLINE 0 0 0
mirror-0 ONLINE 0 0 0
sdb4 ONLINE 0 1 0
sdc4 ONLINE 0 0 0
cache
sda3 ONLINE 0 0 0
errors: No known data errors
root@tubman:~# smartctl -i -qnoserial /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:02:32 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
root@tubman:~# smartctl -a -qnoserial /dev/sdb grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 086 086 000 Old_age Always - 12464 (206 202 0)
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 10966h+55m+23.757s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 21107792664
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 3201579750
21107792664 LBAs * 512 byte/LBA), which
is about two full writes. According to its specification, this
device is supposed to support 55 TB/year of writes, so we're far below
spec. Note that are still far from the "non-recoverable read error per
bits" spec (1 per 10E15), as we've basically read 13E12 bits
(3201579750 LBAs * 512 byte/LBA = 13E12 bits).
It's likely this disk was made in 2018, so it is in its fourth
year.
Interestingly, /dev/sdc is also a Seagate drive, but of a different
series:
root@tubman:~# smartctl -qnoserial -i /dev/sdb
smartctl 7.2 2020-12-30 r5155 [x86_64-linux-5.10.0-15-amd64] (local build)
Copyright (C) 2002-20, Bruce Allen, Christian Franke, www.smartmontools.org
=== START OF INFORMATION SECTION ===
Model Family: Seagate BarraCuda 3.5
Device Model: ST4000DM004-2CV104
Firmware Version: 0001
User Capacity: 4,000,787,030,016 bytes [4.00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 5425 rpm
Form Factor: 3.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ACS-3 T13/2161-D revision 5
SATA Version is: SATA 3.1, 6.0 Gb/s (current: 3.0 Gb/s)
Local Time is: Tue Oct 11 11:21:35 2022 EDT
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
root@tubman:~# smartctl -a -qnoserial /dev/sdc grep -e Head_Flying_Hours -e Power_On_Hours -e Total_LBA -e 'Sector Sizes'
Sector Sizes: 512 bytes logical, 4096 bytes physical
9 Power_On_Hours 0x0032 059 059 000 Old_age Always - 36240
240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 33994h+10m+52.118s
241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 30730174438
242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51894566538
Head_Flying_Hours, and over 4 years (4 years and
48 days) of Power_On_Hours. The copyright date on that drive's
specs goes back to 2016, so it's a much older drive.
SMART self-test succeeded.
Remaining issues
- TODO: move send/receive backups to offsite host, see also
zfs for alternatives to syncoid/sanoid there
- TODO: setup backup cron job (or timer?)
- TODO: swap still not setup on curie, see zfs
- TODO: document this somewhere: bpool and rpool are both pools and
datasets. that's pretty confusing, but also very useful because it
allows for pool-wide recursive snapshots, which are used for the
backup system
fio improvements
I really want to improve my experience with fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
... except the jobs are actually started in parallel, even though they
are stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
fio. Right now, I'm just
cargo-culting stuff from other folks and I don't really like
it. stressant is a good example of my struggles, in the sense
that it doesn't really work that well for disk tests.
I would love to have just a single .fio job file that lists multiple
jobs to run serially. For example, this file describes the above
workload pretty well:
[global]
# cargo-culting Salter
fallocate=none
ioengine=posixaio
runtime=60
time_based=1
end_fsync=1
stonewall=1
group_reporting=1
# no need to drop caches, done by default
# invalidate=1
# Single 4KiB random read/write process
[randread-4k-4g-1x]
rw=randread
bs=4k
size=4g
numjobs=1
iodepth=1
[randwrite-4k-4g-1x]
rw=randwrite
bs=4k
size=4g
numjobs=1
iodepth=1
# 16 parallel 64KiB random read/write processes:
[randread-64k-256m-16x]
rw=randread
bs=64k
size=256m
numjobs=16
iodepth=16
[randwrite-64k-256m-16x]
rw=randwrite
bs=64k
size=256m
numjobs=16
iodepth=16
# Single 1MiB random read/write process
[randread-1m-16g-1x]
rw=randread
bs=1m
size=16g
numjobs=1
iodepth=1
[randwrite-1m-16g-1x]
rw=randwrite
bs=1m
size=16g
numjobs=1
iodepth=1
stonewall'd, as far as I can tell by the reports. I sent a
mail to the fio mailing list for clarification.
It looks like the jobs are started in parallel, but actual
(correctly) run serially. It seems like this might just be a matter of
reporting the right timestamps in the end, although it does feel like
starting all the processes (even if not doing any work yet) could
skew the results.
Hangs during procedure
During the procedure, it happened a few times where any ZFS command
would completely hang. It seems that using an external USB drive to
sync stuff didn't work so well: sometimes it would reconnect under a
different device (from sdc to sdd, for example), and this would
greatly confuse ZFS.
Here, for example, is sdd reappearing out of the blue:
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
Next time I run a ZFS command (say zpool list), the command
completely hangs (D state) and this comes up in the logs:
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
Here's another example, where you see the USB controller bleeping out
and back into existence:
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
I understand those are rather extreme conditions: I would fully expect
the pool to stop working if the underlying drives disappear. What
doesn't seem acceptable is that a command would completely hang like
this.
References
See the zfs documentation for more information about ZFS,
and tubman for another installation and migration procedure.
May 19 11:22:53 curie kernel: [ 699.820301] scsi host4: uas
May 19 11:22:53 curie kernel: [ 699.820544] usb 2-1: authorized to connect
May 19 11:22:53 curie kernel: [ 699.922433] scsi 4:0:0:0: Direct-Access ROG ESD-S1C 0 PQ: 0 ANSI: 6
May 19 11:22:53 curie kernel: [ 699.923235] sd 4:0:0:0: Attached scsi generic sg2 type 0
May 19 11:22:53 curie kernel: [ 699.923676] sd 4:0:0:0: [sdd] 1953525168 512-byte logical blocks: (1.00 TB/932 GiB)
May 19 11:22:53 curie kernel: [ 699.923788] sd 4:0:0:0: [sdd] Write Protect is off
May 19 11:22:53 curie kernel: [ 699.923949] sd 4:0:0:0: [sdd] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA
May 19 11:22:53 curie kernel: [ 699.924149] sd 4:0:0:0: [sdd] Optimal transfer size 33553920 bytes
May 19 11:22:53 curie kernel: [ 699.961602] sdd: sdd1 sdd2 sdd3 sdd4
May 19 11:22:53 curie kernel: [ 699.996083] sd 4:0:0:0: [sdd] Attached SCSI disk
May 19 11:34:21 curie kernel: [ 1387.914843] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=71344128 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914859] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=205565952 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914874] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272789504 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.914906] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=270336 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914932] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073225728 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.914948] zio pool=bpool vdev=/dev/sdc3 error=5 type=1 offset=1073487872 size=8192 flags=b08c1
May 19 11:34:21 curie kernel: [ 1387.915165] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=272793600 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915183] zio pool=bpool vdev=/dev/sdc3 error=5 type=2 offset=339853312 size=4096 flags=184880
May 19 11:34:21 curie kernel: [ 1387.915648] WARNING: Pool 'bpool' has encountered an uncorrectable I/O failure and has been suspended.
May 19 11:34:21 curie kernel: [ 1387.915648]
May 19 11:37:25 curie kernel: [ 1571.558614] task:txg_sync state:D stack: 0 pid: 997 ppid: 2 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.558623] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.558640] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.558650] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.558670] schedule_timeout+0x8b/0x140
May 19 11:37:25 curie kernel: [ 1571.558675] ? __next_timer_interrupt+0x110/0x110
May 19 11:37:25 curie kernel: [ 1571.558678] io_schedule_timeout+0x4c/0x80
May 19 11:37:25 curie kernel: [ 1571.558689] __cv_timedwait_common+0x12b/0x160 [spl]
May 19 11:37:25 curie kernel: [ 1571.558694] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.558702] __cv_timedwait_io+0x15/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.558816] zio_wait+0x129/0x2b0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.558929] dsl_pool_sync+0x461/0x4f0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559032] spa_sync+0x575/0xfa0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559138] ? spa_txg_history_init_io+0x101/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559245] txg_sync_thread+0x2e0/0x4a0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559354] ? txg_fini+0x240/0x240 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559366] thread_generic_wrapper+0x6f/0x80 [spl]
May 19 11:37:25 curie kernel: [ 1571.559376] ? __thread_exit+0x20/0x20 [spl]
May 19 11:37:25 curie kernel: [ 1571.559379] kthread+0x11b/0x140
May 19 11:37:25 curie kernel: [ 1571.559382] ? __kthread_bind_mask+0x60/0x60
May 19 11:37:25 curie kernel: [ 1571.559386] ret_from_fork+0x22/0x30
May 19 11:37:25 curie kernel: [ 1571.559401] task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
May 19 11:37:25 curie kernel: [ 1571.559404] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559409] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559412] ? __kmalloc_node+0x141/0x2b0
May 19 11:37:25 curie kernel: [ 1571.559417] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559420] schedule_preempt_disabled+0xa/0x10
May 19 11:37:25 curie kernel: [ 1571.559424] __mutex_lock.constprop.0+0x133/0x460
May 19 11:37:25 curie kernel: [ 1571.559435] ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
May 19 11:37:25 curie kernel: [ 1571.559537] spa_all_configs+0x41/0x120 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559644] zfs_ioc_pool_configs+0x17/0x70 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559752] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559758] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.559860] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.559866] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.559869] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.559873] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.559876] RIP: 0033:0x7fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559878] RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.559881] RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
May 19 11:37:25 curie kernel: [ 1571.559883] RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
May 19 11:37:25 curie kernel: [ 1571.559885] RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
May 19 11:37:25 curie kernel: [ 1571.559886] R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
May 19 11:37:25 curie kernel: [ 1571.559888] R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
May 19 11:37:25 curie kernel: [ 1571.559980] task:zpool state:D stack: 0 pid:11815 ppid: 3816 flags:0x00004000
May 19 11:37:25 curie kernel: [ 1571.559983] Call Trace:
May 19 11:37:25 curie kernel: [ 1571.559988] __schedule+0x282/0x870
May 19 11:37:25 curie kernel: [ 1571.559992] schedule+0x46/0xb0
May 19 11:37:25 curie kernel: [ 1571.559995] io_schedule+0x42/0x70
May 19 11:37:25 curie kernel: [ 1571.560004] cv_wait_common+0xac/0x130 [spl]
May 19 11:37:25 curie kernel: [ 1571.560008] ? add_wait_queue_exclusive+0x70/0x70
May 19 11:37:25 curie kernel: [ 1571.560118] txg_wait_synced_impl+0xc9/0x110 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560223] txg_wait_synced+0xc/0x40 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560325] spa_export_common+0x4cd/0x590 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560430] ? zfs_log_history+0x9c/0xf0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560537] zfsdev_ioctl_common+0x697/0x870 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560543] ? _copy_from_user+0x28/0x60
May 19 11:37:25 curie kernel: [ 1571.560644] zfsdev_ioctl+0x53/0xe0 [zfs]
May 19 11:37:25 curie kernel: [ 1571.560649] __x64_sys_ioctl+0x83/0xb0
May 19 11:37:25 curie kernel: [ 1571.560653] do_syscall_64+0x33/0x80
May 19 11:37:25 curie kernel: [ 1571.560656] entry_SYSCALL_64_after_hwframe+0x44/0xa9
May 19 11:37:25 curie kernel: [ 1571.560659] RIP: 0033:0x7fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560661] RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
May 19 11:37:25 curie kernel: [ 1571.560664] RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
May 19 11:37:25 curie kernel: [ 1571.560666] RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
May 19 11:37:25 curie kernel: [ 1571.560667] RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
May 19 11:37:25 curie kernel: [ 1571.560669] R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
May 19 11:37:25 curie kernel: [ 1571.560671] R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
mai 19 11:38:39 curie kernel: usb 2-1: USB disconnect, device number 2
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronizing SCSI cache
mai 19 11:38:39 curie kernel: sd 4:0:0:0: [sdd] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
mai 19 11:39:25 curie kernel: INFO: task zed:1564 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zed state:D stack: 0 pid: 1564 ppid: 1 flags:0x00000000
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: ? __kmalloc_node+0x141/0x2b0
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: schedule_preempt_disabled+0xa/0x10
mai 19 11:39:25 curie kernel: __mutex_lock.constprop.0+0x133/0x460
mai 19 11:39:25 curie kernel: ? nvlist_xalloc.part.0+0x68/0xc0 [znvpair]
mai 19 11:39:25 curie kernel: spa_all_configs+0x41/0x120 [zfs]
mai 19 11:39:25 curie kernel: zfs_ioc_pool_configs+0x17/0x70 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fcf0ef32cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007fcf0e181618 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055b212f972a0 RCX: 00007fcf0ef32cc7
mai 19 11:39:25 curie kernel: RDX: 00007fcf0e181640 RSI: 0000000000005a04 RDI: 000000000000000b
mai 19 11:39:25 curie kernel: RBP: 00007fcf0e184c30 R08: 00007fcf08016810 R09: 00007fcf08000080
mai 19 11:39:25 curie kernel: R10: 0000000000080000 R11: 0000000000000246 R12: 000055b212f972a0
mai 19 11:39:25 curie kernel: R13: 0000000000000000 R14: 00007fcf0e181640 R15: 0000000000000000
mai 19 11:39:25 curie kernel: INFO: task zpool:11815 blocked for more than 241 seconds.
mai 19 11:39:25 curie kernel: Tainted: P IOE 5.10.0-14-amd64 #1 Debian 5.10.113-1
mai 19 11:39:25 curie kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
mai 19 11:39:25 curie kernel: task:zpool state:D stack: 0 pid:11815 ppid: 2621 flags:0x00004004
mai 19 11:39:25 curie kernel: Call Trace:
mai 19 11:39:25 curie kernel: __schedule+0x282/0x870
mai 19 11:39:25 curie kernel: schedule+0x46/0xb0
mai 19 11:39:25 curie kernel: io_schedule+0x42/0x70
mai 19 11:39:25 curie kernel: cv_wait_common+0xac/0x130 [spl]
mai 19 11:39:25 curie kernel: ? add_wait_queue_exclusive+0x70/0x70
mai 19 11:39:25 curie kernel: txg_wait_synced_impl+0xc9/0x110 [zfs]
mai 19 11:39:25 curie kernel: txg_wait_synced+0xc/0x40 [zfs]
mai 19 11:39:25 curie kernel: spa_export_common+0x4cd/0x590 [zfs]
mai 19 11:39:25 curie kernel: ? zfs_log_history+0x9c/0xf0 [zfs]
mai 19 11:39:25 curie kernel: zfsdev_ioctl_common+0x697/0x870 [zfs]
mai 19 11:39:25 curie kernel: ? _copy_from_user+0x28/0x60
mai 19 11:39:25 curie kernel: zfsdev_ioctl+0x53/0xe0 [zfs]
mai 19 11:39:25 curie kernel: __x64_sys_ioctl+0x83/0xb0
mai 19 11:39:25 curie kernel: do_syscall_64+0x33/0x80
mai 19 11:39:25 curie kernel: entry_SYSCALL_64_after_hwframe+0x44/0xa9
mai 19 11:39:25 curie kernel: RIP: 0033:0x7fdc23be2cc7
mai 19 11:39:25 curie kernel: RSP: 002b:00007ffc8c792478 EFLAGS: 00000246 ORIG_RAX: 0000000000000010
mai 19 11:39:25 curie kernel: RAX: ffffffffffffffda RBX: 000055942ca49e20 RCX: 00007fdc23be2cc7
mai 19 11:39:25 curie kernel: RDX: 00007ffc8c792490 RSI: 0000000000005a03 RDI: 0000000000000003
mai 19 11:39:25 curie kernel: RBP: 00007ffc8c795e80 R08: 00000000ffffffff R09: 00007ffc8c792310
mai 19 11:39:25 curie kernel: R10: 000055942ca49e30 R11: 0000000000000246 R12: 00007ffc8c792490
mai 19 11:39:25 curie kernel: R13: 000055942ca49e30 R14: 000055942aed2c20 R15: 00007ffc8c795a40
 I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is:
I m trying to replace my old OpenPGP key with a new one. The old key wasn t compromised or lost or anything
bad. Is still valid, but I plan to get rid of it soon. It was created in 2013.
The new key id fingerprint is: 





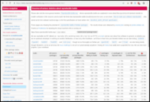


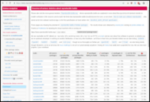
 One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post:
One month ago I started work on a new side project which is now up and running, and deserving on an introductory blog post: 
 Finally, TIL, what can all be the reason for systemd services to hang indefinitely. The internet is flooded with numerous reports on this topic but no clear answers. So no more uselessly marked workarounds like:
Finally, TIL, what can all be the reason for systemd services to hang indefinitely. The internet is flooded with numerous reports on this topic but no clear answers. So no more uselessly marked workarounds like: